
Science fiction writer William Gibson is often credited with saying that the future is already here—it’s just not evenly distributed yet. The same could be said of AI in life sciences. It’s already here: In a 2024 study, the life sciences rank fourth in AI maturity behind the tech, defense, and automotive sectors. AI cut years off the time it took to detect antigens for the COVID-19 vaccine and discovered a new drug candidate for liver cancer in 30 days.
It’s just not evenly distributed. Most of the early investment and attention in AI for life sciences has gone to drug discovery, with headlines driven by big investments in high-performance computers that can spawn synthetic biomolecules. But for the vast majority of industry participants, the impact of Scientific AI will be more widespread—the equivalent of tightening a thousand screws at once—with an aggregate impact just as significant, if not more so, than a $1 billion supercomputer. Imagine Scientific AI, analytics, and dashboards leading to hundreds of critical, validated improvements across the pharma value chain. Automating, optimizing, or avoiding errors and repeated steps across dozens of scientific functions could shave months off a therapy’s time-to-market and return weeks of precious time to scientists.
TetraScience recently helped a large biopharma use AI to predict deviations in quality control testing and identify their root causes. The models reduced deviations by 80% and sped up investigation closure times by 90%. And that’s just one lab. The company has 150 quality control labs. If each generates 700 to 1,000, that’s roughly 120,000 deviations annually. Figure it takes two full-time employees three months to trace each deviation, and those lab workers spend 60% of their time writing reports. Eliminating 80% of the deviations equals $4 billion in savings that could transfer to more strategic science. That’s a Mounjaro or Wegovy hiding in plain sight. And that’s just one use case. Multiply this kind of impact across hundreds, if not thousands of Scientific AI use cases, and you can start to see the aggregate value of tightening screws.
How does an organization go from having a handful of Scientific AI use cases in production to dozens or even hundreds? By taking a factory-like, industrialized approach to building and deploying those use cases. We define a scientific use case as the atomic unit of value creation where analytics/ML/AI meets engineered scientific data. It’s centered around the needs of scientists and designed to fulfill scientific needs/outcomes that may not be currently possible or even imagined. For example, the Chromatography Insights dashboard powered by TetraScience and Databricks automatically incorporates existing and historical data across multiple chromatography data systems (CDSs) to track—and act on—key metrics such as peak symmetry factor, retention time, and peak area across multiple systems and users. Other use cases include an automated data collection pipeline for accelerating batch release programs or an AI optimization model for purification process development. Many of these use cases may already be documented and ready to come off the shelf.
The first step along the assembly line is the discovery and design phase. Subject matter experts collaborate (ideally) with their IT and data engineering counterparts to quantify the ROI and build a prototype. Stakeholders should then regularly convene to prioritize the project queue and finalize the solution design documents that inform the implementation and go-live phases. The teams should learn and document each use case once it’s in production and feed that intelligence back into the design-discovery phases, and then you keep doing it over again for each new use case. The flow looks something like the infographic below.
The Scientific Use Case Factory
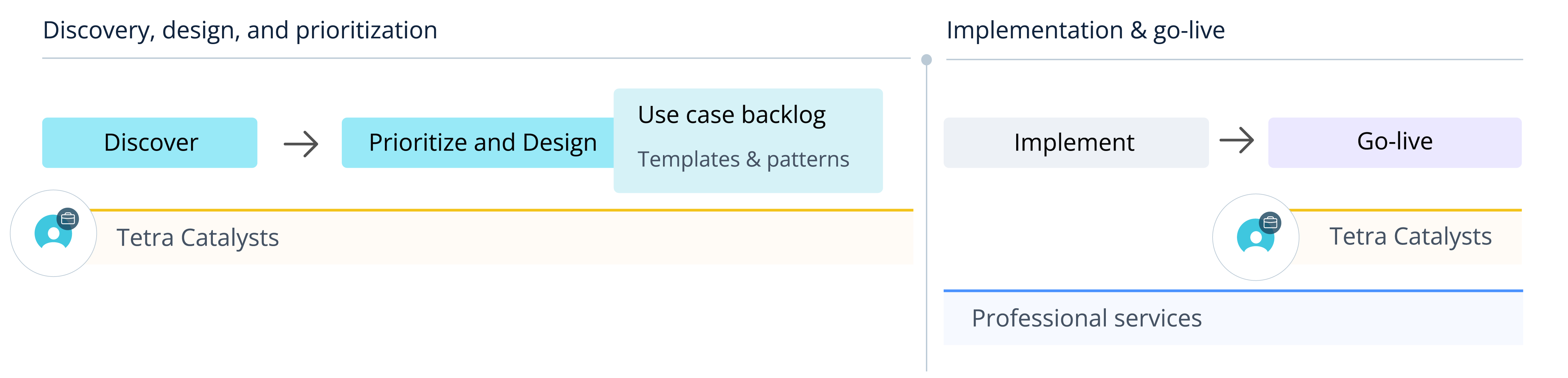
The critical obstacle to productizing scientific use cases is the quality of an organization’s scientific data. Scientific use cases, especially those powered by AI models, need large-scale, liquid, traceable, and compliant data sets. Scientific data is complex, multimodal, and unstructured, so it requires deep and nuanced scientific taxonomies and ontologies to contextualize it.
Unfortunately, most scientific data sets are siloed, sub-scale, illiquid, and widely dispersed across the pharmaceutical organization and their multiple CRO/CDMO partners and geographic regions. Given the scope and urgency of the data challenge, the viable path forward is for life sciences organizations to begin migrating their scientific data into an open and modern technology stack that’s purpose-built for Scientific AI.
What does this stack look like? It’s cloud-native, scientific data-centric, and vendor-agnostic. It can combine and harmonize data sources throughout the modern laboratory with validated, industrialized integrations. It provides advanced data management capabilities like cloud-based storage, archive, restore, and access control functionality. It makes governed data assets discoverable and reusable so organizations can share data easily across systems and platforms to save cost and time. It’s built on world-class cloud infrastructure that excels at developing and safely deploying AI and machine learning models. It’s scalable enough to handle even the most compute-intensive workloads for analytics, AI, and ML.
TetraScience recently partnered with Databricks to significantly enhance the adoption of Scientific AI in the life sciences sector. This collaboration brings together the best of two worlds: TetraScience contributes its purpose-built scientific data and AI cloud, deep scientific domain expertise, and a robust partner ecosystem. Databricks offers its Data Intelligence Platform, which lays the foundation for robust data engineering, analytics, and AI model training efforts. Its innovative lakehouse architecture supports multimodal data integration, which is crucial for Scientific AI. It enables the integration of various data types in real time and provides comprehensive tooling for the entire machine learning (ML) lifecycle.
Critically, Databricks' platform also includes AI-powered Business Intelligence capabilities that enable access to data analytics through natural language. This remarkable feature opens up analytics to bench scientists who may not have any programming background, democratizing data insights across the board. Through the synergy of TetraScience and Databricks, data scientists, data engineers, and IT teams are empowered to synchronize data from numerous instruments seamlessly, making it readily available in the Unity Catalog. This facilitates data discoverability, governance, advanced analytics, and Generative AI workloads, marking a significant leap forward in scientific research capabilities.
The transformative power of AI in life sciences lies in groundbreaking discoveries and in the widespread, practical applications that can revolutionize everyday processes across the industry. Building Scientific AI use-case factories can unlock immense value from the intricate data that fuels the life sciences. This requires a modern, open, and scalable technology stack, as exemplified by the TetraScience and Databricks partnership. As more organizations embrace this approach, the future of life sciences will be marked by enhanced efficiency, accelerated innovation, and, ultimately, better outcomes for patients worldwide. The future is here; it’s time to distribute it more evenly.
Naveen Kondapalli is the SVP of Product and Engineering at TetraScience. Amir Kermany is the Senior Industry Solutions Director for Healthcare and Life Sciences at Databricks.